Machine learning (ML) models rarely make it to production. Multiple sources report that over 90% of ML models do not reach their users and do not benefit businesses. What it takes to get into those 10% of success cases or should we accept the fact that 10% of success is written in the DNA of AI?
Problem? Look out for context!
While working in various advanced analytics teams over the past 7 years I learnt that solving exact same problem in different contexts requires different approaches.
At the very beginning of each project that aims to build data-driven product we should set aside some time to define:
- What is the problem – what are we trying to solve there?
- What is the context of the problem – what is around this problem – data, assumptions, limitations?
- What is our knowledge – have we completed some relevant courses or built similar models in the past?
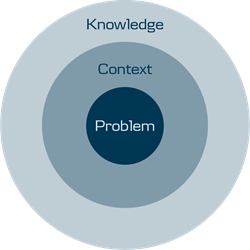
Any data-driven product development should start with the problem in a defined context and with a team that holds certain knowledge that can be applied while solving the problem. A lot of ML models start with intention ‘let’s make something cool’ and it is fine to try out new algorithms and experiment. However, when you wish to see your model running in production and you are building the very first version, I strongly suggest going with the simplest solution.

ML model development is a route from idea to production with some key milestones on its way. It is like a board game with certain rules that need to be respected.
Teamwork makes the dream work
Talking about rules, you may like it or not, there is one rule that should be fulfilled in all of the board games – minimum number of players. The field of AI is often seen as super complicated and remote to other daily businesses. Meanwhile, having a multidisciplinary team including business stakeholders is one of key elements of a successful ML model.
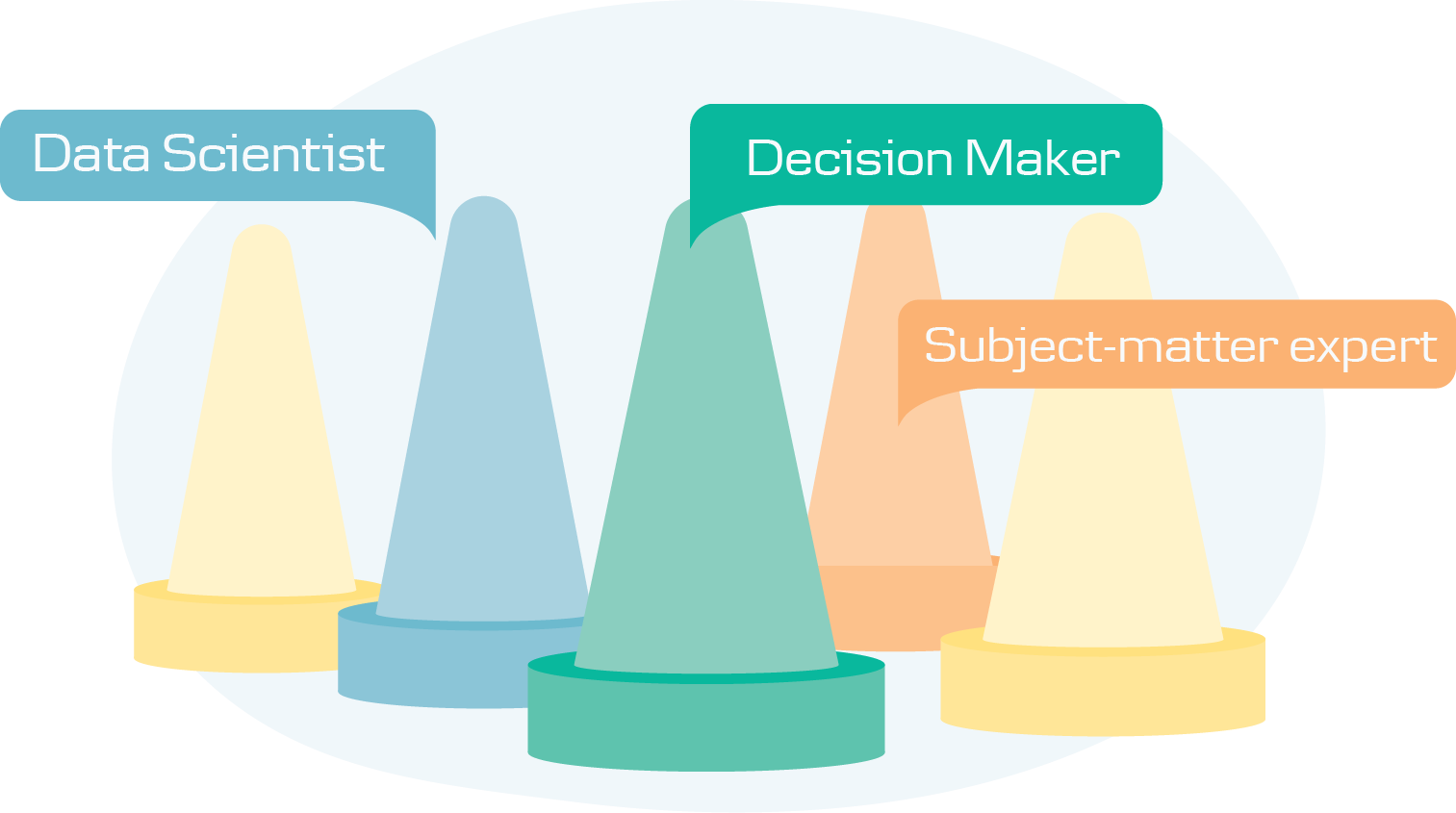
The key roles in each ML product development process are the following:
Data scientist – the one who will be applying statistical methods and programming knowledge in order to solve the problem.
Subject-matter expert – the one who understands the problem and the context of the problem. This person will be responsible for making sure that mathematical – technical solution is relevant (and will be relevant) for the suggested business problem.
Decision maker – the one who will be making all the tough decisions, including changes of the project, adjustments, approving assumptions, simplifications, avoiding over-complications.
There might be more roles introduced if needed (e.g data engineers, data ops, business analysts), but the goal is to keep this team working together all the way through, respecting all the roles.
How to measure ‘Good enough’?
When type of the problem and tools have been discussed, hands-on work should begin. Right? Well, not quite so. Before throwing yourself into big data, set aside some time for RIM (Really Important Meeting). I call it ‘Good Enough’ meeting.
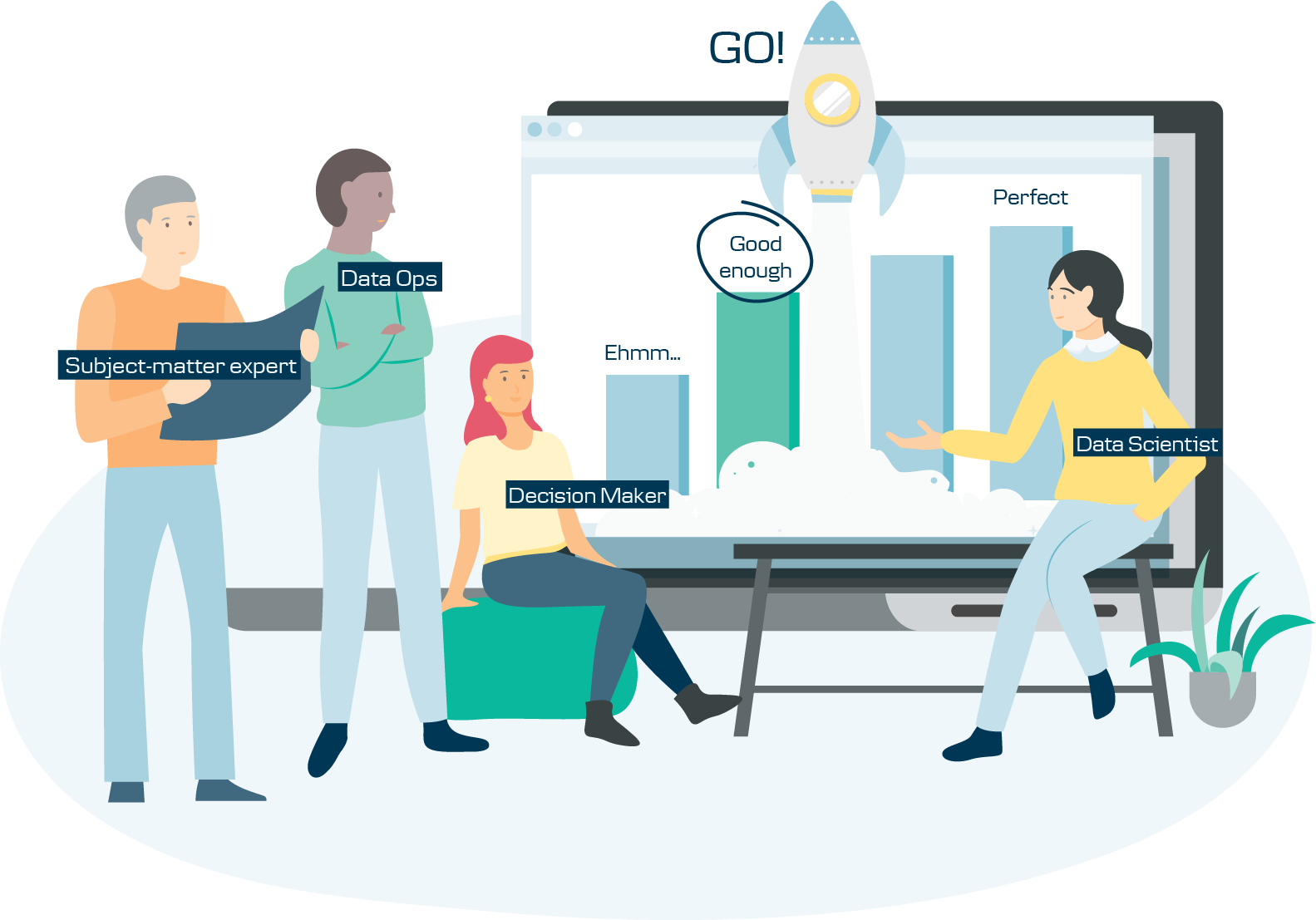
In a business environment, Data Science usually balances between an ideal mathematical model and business needs. On the one end of scale is the pride of having cutting-edge algorithm implemented, on the other one – a need to have any model in production ASAP. Setting ‘good enough’ criteria set will allow you to measure model results taking both data science and business perspectives.
It’s a data’s data’s data’s world
But it would be nothing without human’s interpretation
There are plenty of articles and training courses teaching how to technically approach data, but not that many of how to interpret data. I would love to see a course called ‘Human – Data interaction’ teaching us how to create meaningful and unbiased relation between data scientist and data.
Everything that we see, we see through the eyes of our own experience and that is unique for every single human being. In the context of psychology, we are smart enough to recognize that we might share different views or values, but when we look at numbers, somehow, we magically fall into illusion that numbers are presenting the single and only truth that data is providing us. However, numbers are the outcome in the specific (simplified) format of events, behavior or metrics often generated by humans. Numbers give us an illusion of accuracy.
What to do then? I would say apply methodology developed by psychologists:
Acknowledge your biases
Set up criteria and processes working with data
Review findings with project team
Algorithms or why data scientists are businesses’ doctors
Once my grandfather asked me ‘What do data scientists do?’. I explained him that data scientists in business are like doctors. Business people come to them when they face some problems. Data scientists then have to listen carefully and identify the symptoms. Symptoms might be primary or secondary and it’s data scientist’s job to diagnose the problem. As real doctors, data scientists are writing prescriptions – algorithms, to heal their patients’ problem.
Algorithms are like pills – there are so many of them and it’s a doctor’s job to find the right pills for the problem. Machine learning algorithms are like antibiotics – they are effective and strong, but they are not meant to solve each and every problem. Always try the simplest algorithms first and if, and only if, they are not good enough, jump to more complex algorithms. Why take antibiotics (Neural Networks) if paracetamol (Regression) can solve your problem?
Overcomplicating the process of solving the problem by selecting complex algorithms is probably the most common reason why ML models don’t face production. Good data scientists can grasp complex algorithms, but also understand when not to use them.
When modelling is over
The process of building ML model is usually tiring. There is a push from business to deliver faster, there are issues with data, assumptions that do not confirm themselves. The moment when data scientists claim that they might have a model which works (even if it’s in their jupyter notebooks) has often been considered the end of building a model. At that point, the project team is tired and keen to close the project, while the most important work should begin – validation of the model.
The idea of validation suggests that model should be put in different contexts, through different scenarios and results should be reviewed. The stability, accuracy, learnability and limitations of the model should be evaluated. Both statistical measures and business assumptions should be tested carefully. You might find out that the model performs better under certain circumstances. That would require talking to model’s stakeholders and, maybe, redefining how and when this model should be used.
There is no way back…
Quoting Little Prince ‘you become responsible forever for what you have tamed’. The modern version of this quote would be ‘you become responsible for what you have tamed until you leave your job’.
Not all models should go into production. Realization that there is no need for a particular model is also a valuable result. A simple dashboard with no ML model algorithm is also a result.

Is there anything we can do to put more models into production? I would say – yes. Always start with the problem, learn the problem, learn the context of the problem, try to be mindful of human-data interaction subtleties, do not overcomplicate solution with complex algorithms and respect all types of results.

About the author: "I started my career as a data scientist 7 years ago. Danske Bank was making first steps towards data science and I was one of a few to make those steps. I was exploring and experimenting and that led me to moments of success and failure. Now I am leading data science team and mentoring people who want to become data scientists."
Areas of interest: Artificial Intelligence, Data Science, Data Ops, Data Engineering
Curious to know more about our Tech @Danske? Visit this page.
